![Challenges in Fine-Tuning Computer Vision Models [banner]](https://www.infopulse.com/uploads/media/banner-1920x528-7-common-pitfalls-of-fine-tuning-computer-vision-models.jpg)
7 Common Pitfalls of Fine-Tuning Computer Vision Models
Common Pitfalls of Fine-Tuning a Computer Vision Model
Over the last decade, there have been significant advances in computer vision technology. Large-scale public image datasets like ImageNet made hand-annotated training data more accessible.
Robust models are available in open-source repositories or licensed through cloud service providers. For instance, Azure AI Vision offers API-based access to potent optical character recognition (OCR) models and responsible facial recognition algorithms.
Still, certain complexities remain, especially when it comes to productizing computer vision models and tailoring them to a specific project. Here are the seven most common pitfalls to watch out for.
1. Underestimating Project Scope and Requirements
Requirements gathering and validation are critical for ensuring project feasibility. Depending on your business case, there will always be tradeoffs in performance versus costs. State-of-the-art computer vision algorithms deliver superior accuracy and recall even in complex conditions (e.g., moving objects or poor lighting).
The OmniVec model delivers 92.4% accuracy on the ImageNet classification benchmark test but consumes substantial computational resources due to more parameters and processing layers. A more complex and robust algorithm may seem better for a proof of concept (PoC) deployment. However, many business leaders afterward underestimate the costs of scaling such solutions to analyze a high volume of footage (e.g., performing people counts in high-traffic areas or scanning license plate scans on a busy motorway).
Computer vision project costs also include hardware expenses that vary depending on the use case. For simpler scenarios, existing CCTV cameras may suffice if positioned well. For more complex ones, you may need to purchase extra hardware with a better definition or frame rate per second. For example, to enable footfall estimation and consumer behavior analysis with computer vision in a two thousand square meter (20,000+ square feet) mall, the Infopulse team needed to install 50+ cameras on-premise in the optimal configuration to ensure full coverage and support the scenario of tracking customers’ journeys through the mall.
Different requirements can dramatically change the cost of developing and operating a computer vision solution. Performance tradeoffs may be necessary for cost efficiency.

2. Choosing the Wrong Baseline Model
The choice of a pre-trained computer vision model is exorbitant. The breadth of options, however, often makes the choice more challenging. To select the optimal computer vision for fine-tuning, consider the following factors:
- Use case. Computer vision models are usually pre-trained for a specific task. For instance, Kraken and Tesseract are excellent choices for OCR. YOLO and RetinaNet have superior object detection capabilities. One of the best algorithms for action recognition in video is Inception v3. Narrow your search by the use case.
- GPU RAM requirements. Each algorithm will require different GPU RAM, depending on factors like model size, input image size, model parallelism, framework overhead, and data augmentation techniques used. For example, processing multiple images in parallel (using a batch method) can improve model training but can also increase GPU memory usage (and TCO by proxy).
- Performance metrics. When comparing model performance characteristics, pay attention to factors like PR curves, precision, and recall in benchmark tests. Higher performance may seem better, but more complex models have run-time tradeoffs. Hence, settling for 75% accuracy over 80% (if the use case permits) can substantially increase the scalability of your solution.
- Deployment scenario. Depending on where the model will be deployed — on the edge, in the cloud, or using a hybrid scenario — you should also consider factors like portability. Can you easily convert the model to run on different types of edge devices? Is the hardware robust enough to support it?
The above are high-level factors the Infopulse computer vision team usually considers for algorithm selection.
3. Subpar Data Labeling and Annotation Process
Data labeling and annotation are common bottlenecks for computer vision projects. Algorithms need at least 300 images (often 2X-5X more) for each class to yield satisfactory results. Public image datasets may not offer enough relevant visuals. Researchers have observed a slowdown in the growth of image datasets to 8% yearly (compared to 18% and to 31% per year earlier).
Your project will likely involve extra labor expenses on data annotation and labeling. Since these tasks are mostly done manually, there is always room for error. Inaccurate labeling leads to subpar model performance, triggering the need for higher-quality annotation, further increasing the costs.
In addition, models can perform differently in training and production. Google Health's computer vision model for detecting signs of diabetic retinopathy on eye scans delivered 90% accuracy during testing in 10 minutes. However, it failed during a pilot deployment in a Thai hospital, as MIT reports, because the image scans had more noise and were often rejected.
Computer vision algorithms can deliver worse results for a multitude of reasons: poor lighting or visibility conditions, suboptimal camera placements, background biases, or object movement speed. To avoid this, invest in a sizable, variable dataset during training and conduct exhaustive model stress tests to validate its capabilities in challenging operating conditions or against edge use cases.
4. Choosing an Inappropriate Transfer Learning Technique
Transfer learning is the process of using a pre-trained model's features to solve a new, related task with limited data. The two common groups of transfer learning techniques are:
- Feature extraction involves transforming raw input data into a set of informative and non-redundant features that facilitate model learning.
- Fine-tuning adapts a pre-trained model to a specific task by training its final layers with a smaller learning rate on the new dataset.
Feature extraction is a good option when you have a smaller dataset. It also requires less computing resources since you are only retraining new layers with fewer parameters than pre-trained ones. However, feature extraction is prone to overfitting — when the model learns from the noise in the training data to the extent that it negatively impacts its performance on new data.
Fine-tuning is better suited for large and similar datasets to the pre-trained model. It can overfit small datasets with different features, although regularization counters this. Fine-tuning requires more computational resources and time than feature extraction since the entire model is re-trained, but it helps achieve higher model performance for specific use cases.
5. Not Using Data Augmentation
Data augmentation is a technique for artificially expanding and diversifying training datasets. For instance, it can be used by applying image rotation, scaling, flipping, or adding noise to create extra versions of the same images. It’s a cost-effective method for expanding your dataset and training the model on images that are more reflective of real-world conditions.
For the best results, apply combined different data augmentation methods:
- Create a sequence of augmentations
- Change the order of their applications
- Randomize augmentation parameters (e.g., saturation range or rotation angle)
- Create a random probability for applying augmentations.
For example, ImageNet, an image classification neural network with 60 million parameters, was trained using a two-step sequence of data augmentation that helped prevent overfitting.
Caveats: Augmentation may distort data label placements or visibility. Dirty labels introduce noise into the model and worsen its performance, so it is best to keep labels intact.
Also, allocate sufficient resources for data augmentation. CPUs may perform slower augmentation but at a lower cost. GPUs deliver faster results for a bigger price tag. Measure augmentation performance on CPU vs GPU for different types of tasks to find the golden spot.
6. Insufficient Model Evaluation and Testing
Without adequate validation, computer vision models may fail to transfer the training results to real-world applications. The first important rule is to always use separate datasets for training and model validation. Otherwise, you risk overfitting and cannot effectively benchmark different model versions for tracked metrics.
For computer vision tasks, requiring extra pression, for example ADAS features like vehicle or lane detection, consider performing extra stress-tests to validate the algorithms in challenging conditions. A validation dataset should include images in all possible viewing conditions (lighting, viewpoint, material, local background) and some purposefully distorted or occluded ones to ensure the model can handle corner cases.

7. Considering Model Deployment the Final Step
Deploying a fine-tuned computer vision model to production is a major milestone. However, it is not the end of the journey. Computer vision models require observability to ensure reliable performance.
Model drift inevitably occurs over time, either when the distribution of the input data changes (e.g., all new images come in darker lighting) or the underlying task the model was trained to do changes (e.g., the model needs to detect a new object class).
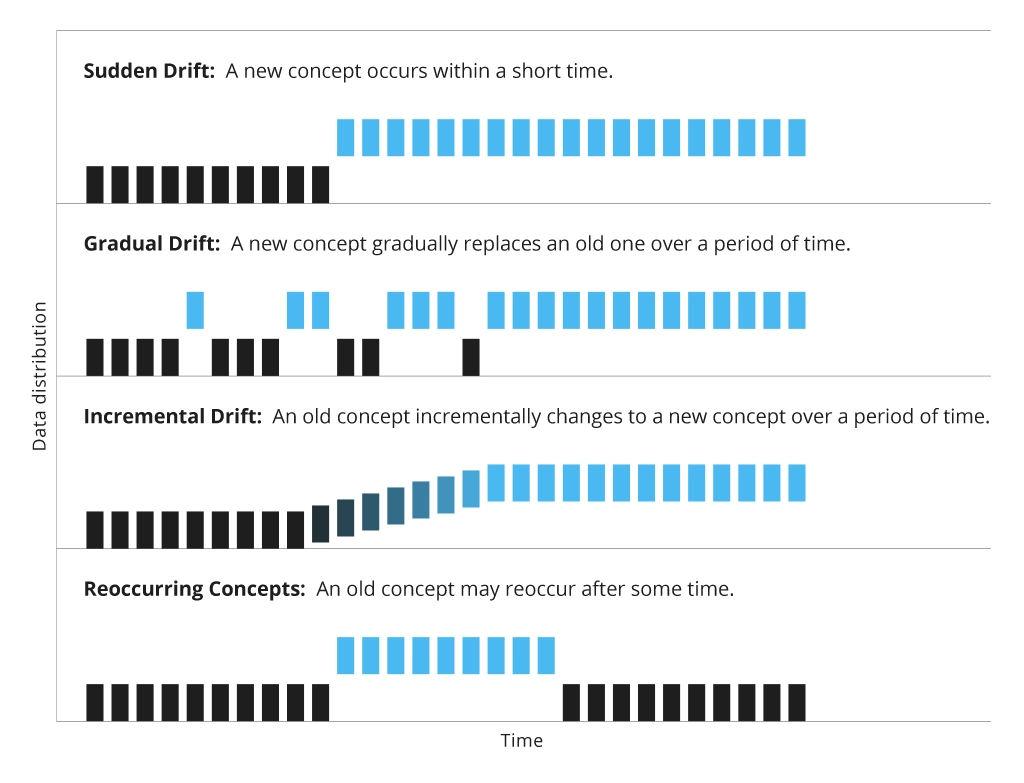
At any rate, model drift leads to poor performance. Implement model observability tools to detect decline in key performance metrics (e.g., recall, precision, detection accuracy) and initiate timely investigations. A good practice is initiating automatic model re-training whenever the performance dips below the acceptable benchmark(s).
Final Thoughts
Computer vision enables a multitude of advanced automation scenarios and new visual analytics use cases. Such solutions have the immense potential to improve operational efficiency, precious quality assurance processes, and the safety of (semi-)autonomous systems. However, all of these use cases require an effective process for fine-tuning, validating, and monitoring computer vision models — an area where Infopulse would be happy to help.
Our team has successfully deployed computer vision-based systems to automate gauge readings, enabled real-time people counts and visual customer analytics for a large Asian retailer, and worked on a number of other projects in the automotive and manufacturing industries.







